Using ScrapeNinja with n8n

n8n is a low-code automation platform that allows you to build automation scenarios without writing code (read a good review of n8n and comparison with Make here). It is very similar to Zapier and Make.com though a bit more technical. A huge advantage of n8n is that it can be self-hosted, or you can opt in for a cloud offering which is quite affordable as well.
ScrapeNinja is a high performance web scraping API that attempts to solve the common challenges web developers face when trying to scrape random e-commerce, social networking or any other website. ScrapeNinja also offers a set of tools to make web scraping easier: cURL converter, ScrapeNinja Playground (with many ScrapeNinja scrapers available for demo purposes), and ScrapeNinja Cheerio Playground.
Integrating ScrapeNinja into n8n is quite easy. Let's see how to do it.
I can scrape via n8n directly, why would I need ScrapeNinja?
n8n can execute HTTP requests and process the result, so technically, it is possible to retrieve output by sending the request directly to a target website. It is a great way to start. However, in a real world, this approach quickly becomes limiting:
- n8n does not support smart retries via rotating proxies,
- it is not very convenient to extract pure JSON data from HTML DOM tree (other than HTML node, which also uses Cheerio.js under the hood but requires using UI to specify CSS extractors, which does not provide the flexibility of custom JS extractors), and
- rendering website as a real browser with JS evaluation is also not possible out of the box.
Also, the JA3 fingerprint of HTTP request of n8n has Node.js fingerprint, which is not as effective as Chrome TLS fingerprint of ScrapeNinja. Cloudflare anti-scraping protection might be triggered by n8n request, while ScrapeNinja (even non-JS engine) can bypass it.
Quickstart (recommended, using ScrapeNinja activity node):
ScrapeNinja got official n8n integration in 2025!
See this thread in n8n community forum.Now it is much more convenient to send requests to ScrapeNinja API, just install the new community node in your self-hosted n8n instance in Settings → Community Nodes by entering "n8n-nodes-scrapeninja" and clicking install. Then get your API key (both RapidAPI and APIRoad API keys are supported), enter the key in your n8n instance into credentials, and now you have ScrapeNinja actions to scrape via real browser and raw network requests! Installation video:
ScrapeNinja n8n node: list of operations
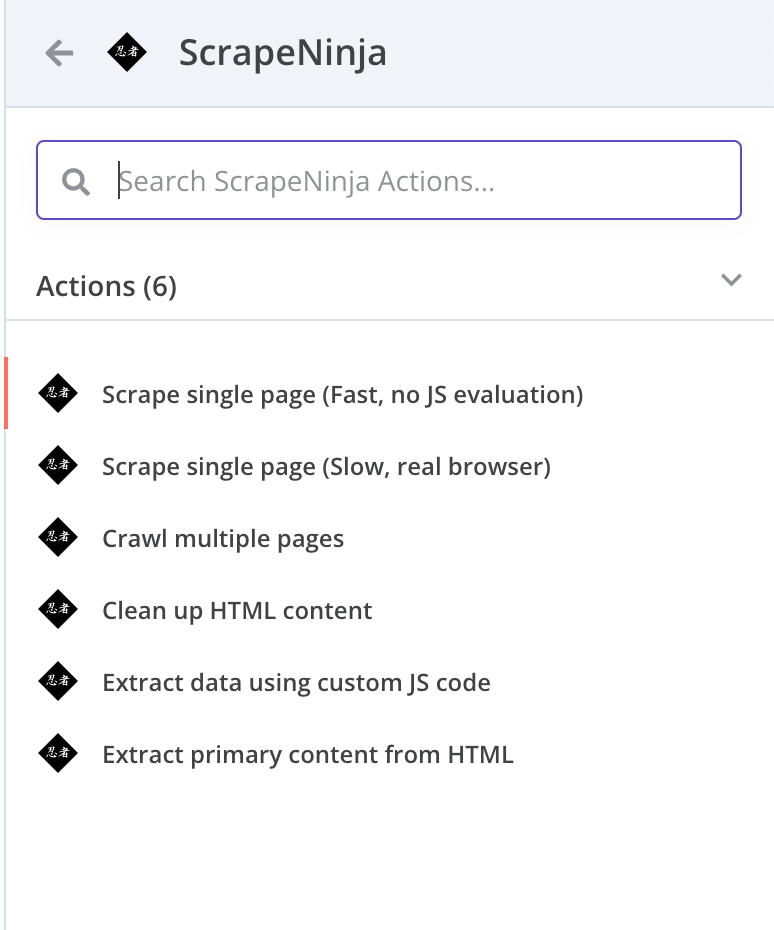
n8n node contains 3 operations which require ScrapeNinja API key:
Scrape- scrape website via fast network request (no JS evaluation)Scrape JS- scrape website via real browser rendering with JS evaluation and screenshot functionalityCrawl website- crawl website, extract all links, and recursively traverse the website putting all data into Postgres database All these operations are using ScrapeNinja API under the hood so they feature rotating proxies from many countries (geos) and many ScrapeNinja features like "retry on text occurrence".
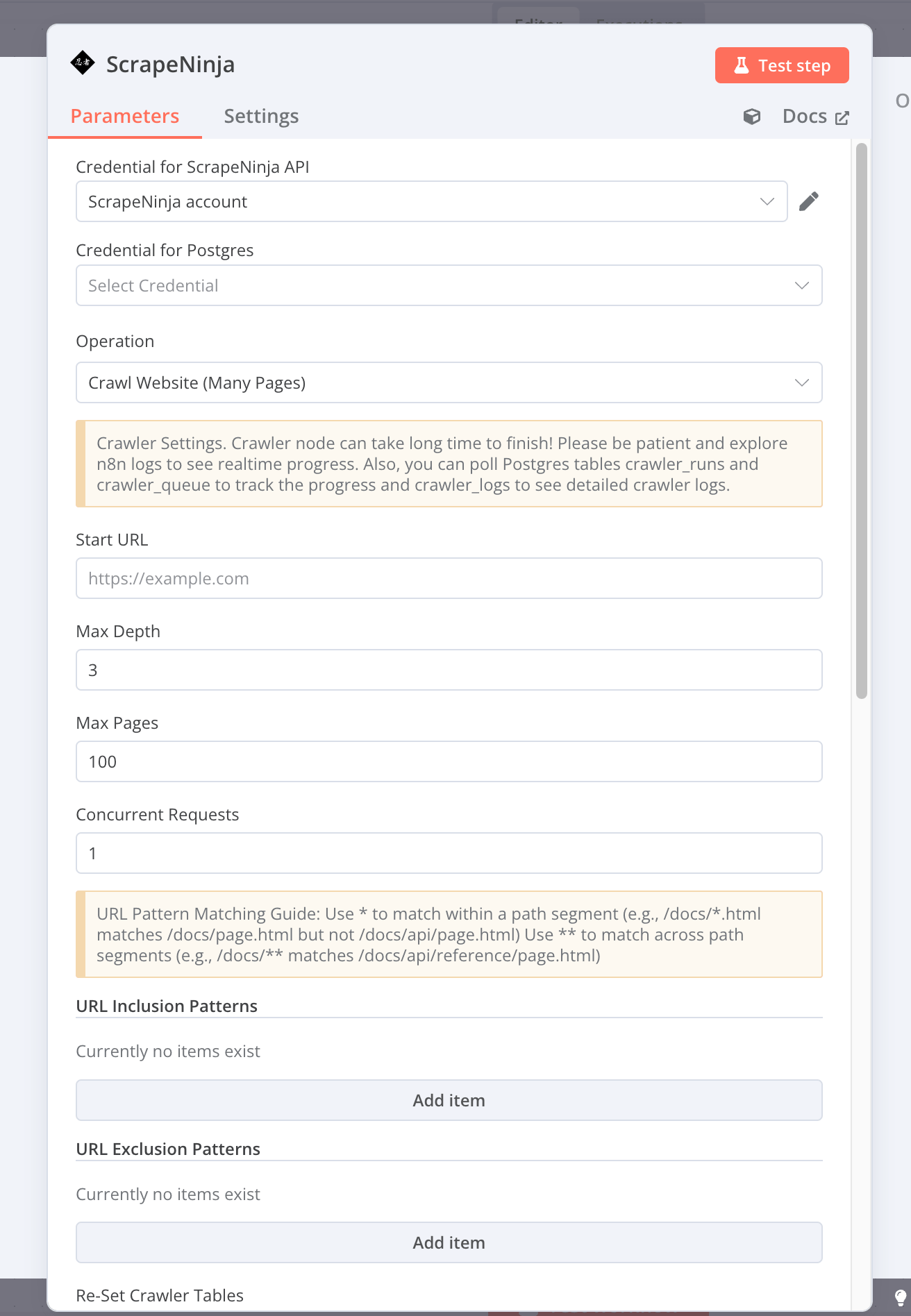
Also, there are operations which do not require API key and are executed directly in your n8n instance:
Clean up HTML content- lossy compression for HTML (useful for passing cleaned HTML into LLM, saves a lot of tokens): remove all inline JavaScript, SVG, reduce non essential whitespace but maintain HTML structure and text nodesExtract data using custom JS code- an alternative to built-in n8n HTML extract node which is also similar to built-in n8n Code node, but is more convenient since it includes instance of Cheerio.js library. Supply HTML and Javascript function (extractor) to execute cheerio instance against the HTML, and get JSON output. ScrapeNinja also provides a simple way to use AI to generate and quickly test the extractor function: ScrapeNinja AI-enhanced Cheerio Playground.Extract primary content from HTML- uses Mozilla Readability library to automagically detect and extract the main text content from the HTML and meta tag attributes like title, description and author (and optionally convert the content into Markdown). Works with 95% success ratio for web pages which have some text content corpus on a web page.
You can still use ScrapeNinja API by sending raw POST request via n8n HTTP node, though this is a more advanced approach:
Advanced start (via HTTP node):
Instead of making n8n send the HTTP request to the target website, you send HTTP POST request to ScrapeNinja API and supply the URL you want to get data from.
The examples below are using cURL utility for brevity. We can use n8n HTTP Request node to do the same thing.
# Let's try to scrape some website... this is a same concept of using n8n HTTP request node to send request directly to a scraped website.
curl https://example.com/product -H "User-Agent: Chrome"
# Output 1, the request failed:
<html><body><h1 style="color: red">Access Denied!</h1><div>This webpage has certain countries forbidden: DE. Your location is: DE</div></body></html>
Okay, this didn't work. let's try the same request with ScrapeNinja, via US proxy pool! ScrapeNinja returns JSON with metadata so we use jq CLI utility here to extract JSON body property.
curl https://scrapeninja.p.rapidapi.com/scrape -d '{"url": "https://example.com/product", "geo":"us"}' -H "Content-Type: application/json" -H "X-Rapidapi-Key: YOUR-KEY" | jq '.body'
# Output 2, via ScrapeNinja:
<html><body><h1 style="color: green">Product Title #1</h1><div class='price'>Price: <span>$321.4</span></div></body></html>
ScrapeNinja Cheerio-powered extractors
Much better! Now let's extract useful data by writing simple JavaScript extractor and sending it to ScrapeNinja cloud. This feature simplifies the process of data extraction and processing, as you don't need to install Cheerio npm package into n8n (and installing npm packages is not possible in n8n Cloud, for example). Read more about ScrapeNinja extractors here.
curl https://scrapeninja.p.rapidapi.com/scrape -d '{"url": "https://example.com/product", "geo":"fr", "extractor": "function extract(html, c) { let $ = c.load(html); return $('.price span').text(); }"}' -H "Content-Type: application/json" -H "X-Rapidapi-Key: YOUR-KEY" | jq '.extractor'
# Output 3, ScrapeNinja with Extractor. ScrapeNinja Cloud executed Cheerio and used supplied JS extractor to retrieve the price from the HTML. Extractor output is put to `extractor` property of ScrapeNinja JSON response.
{ "result": "$321" }
ScrapeNinja real browser engine
ScrapeNinja has a /scrape-js endpoint that uses a real browser to render the website. It can evaluate JavaScript, intercept AJAX calls, and even take screenshots. This is useful when the website relies heavily on JavaScript for rendering content.
Read more about ScrapeNinja architecture on Intro page
# let's top it up a notch. /scrape is using high-perf scraping engine, but what if some real browser rendering is needed?
# Let's use /scrape-js endoint instead, it even takes screenshots and waits for a full page load!
curl https://scrapeninja.p.rapidapi.com/scrape-js -d '{"url": "https://example.com/product", "geo":"fr", "waitForSelector":".price"}' -H "Content-Type: application/json" -H "X-Rapidapi-Key: YOUR-KEY" | jq '.info.screenshot'
# Output 4: the screenshot of a website, via ScrapeNinja real browser rendering engine.
https://cdn.scrapeninja.net/screenshots/website-screenshot.png
# Try ScrapeNinja in a browser: https://scrapeninja.net/scraper-sandbox?slug=hackernews
Converting ScrapeNinja cURL command into n8n HTTP Request node: video demo
Now we know how it works via cURL - let's do the same thing in n8n. It is very easy, thanks to n8n cURL import feature. Here is a 30 second video how you can use ScrapeNinja RapidAPI cURL command and convert it into n8n HTTP Request node:
Of course, it is recommended to extract API key into n8n Credentials if you plan to reuse ScrapeNinja requests in multiple scenarios.
Convert raw HTML into JSON in n8n with ScrapeNinja JS extractors
Now you can copy any ScrapeNinja params into n8n HTTP node and enhance your automation scenarios with web scraping capabilities. For example, in this quick video ScrapeNinja extractor is used to convert HackerNews raw HTML output to structured JSON data: