Overview
ScrapeNinja is a high performance web scraping API that attempts to solve the common challenges web developers face when trying to scrape random e-commerce, social networking or any other website. ScrapeNinja is an API-first SaaS, available on a subscription basis. ScrapeNinja also offers a set of tools to make web scraping easier: cURL converter, ScrapeNinja Playground, and ScrapeNinja Cheerio Playground.
Problems ScrapeNinja Solves
- Anti-scraping Protection: With its high-performance
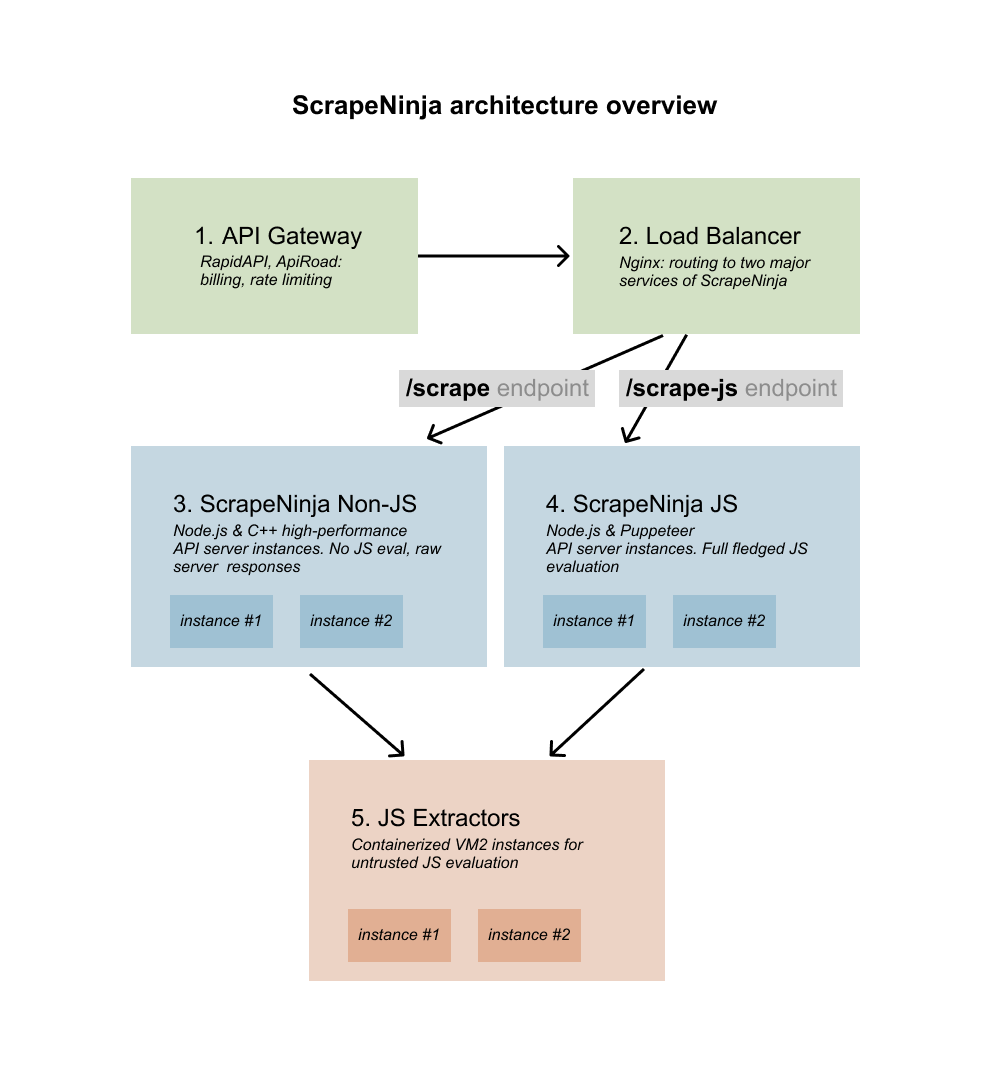
/scrapeengine and Chrome TLS fingerprint, ScrapeNinja effectively bypasses many anti-scraping protections available in the market. - JavaScript Challenges: Many modern websites heavily rely on JavaScript for rendering content. The
/scrape-jsengine can interact with these pages, evaluate JS, intercept AJAX calls, and even make screenshots. - Proxy Issues: Instead of depending on a single source, ScrapeNinja has a rotating set of proxies from various regions. This ensures higher availability and decreases chances of IP bans.
- Data Extraction: Extracting useful data from raw HTML can be challenging. With the Cheerio Extractor functions, users can derive useful data without the need to manually parse through complex HTML structures.
ScrapeNinja Main Features
- Two rendering engines:
- High performance
/scrapeengine, which is fast and has a Chrome TLS fingerprint to bypass many anti-scraping protections available on the market./scrapeengine does not evaluate JS. Read more about TLS fingerprinting and why/scrapeengine was created in this blog post. - Real browser with JS rendering,
/scrape-jsendpoint.scrape-jscan interact with web pages, evaluate JS, intercept AJAX calls, and make screenshots. Read more about/scrape-jsengine in this blog post
- High performance
- Rotating proxies available out of the box (US / EU / Brazil / France / Germany / 4G EU). ScrapeNinja team cooperates with many proxy providers and constantly monitors the proxy health and response quality.
- New feature, Jun 2024: Premium datacenter proxies (50+ countries, tens of thousands of ips in proxy pool) with affordable per-GB pricing (1.5 USD / GB). Useful when basic free proxies fail to achieve good results. Every new ScrapeNinja customer gets 50MB of premium traffic. APIRoad API marketplace signup is required to get the gift and to purchase ScrapeNinja premium proxies. Get premium ScrapeNinja proxies via APIRoad
- Smart retries based on text occurrence, HTTP response status, timeout.
- Cheerio Extractor functions - Javascript functions which launch Cheerio to extract useful data from provided raw target website HTTP response. Extractor functions are executed in ScrapeNinja cloud and are compatible with both scraping engines.
Target audience
The ScrapeNinja Web Scraping API is primarily aimed at fellow developers. It is a fairly low-level web scraping tool designed to be integrated into a higher level system. In order to build a real web scraper using ScrapeNinja, it is highly recommended that you have a basic understanding of how the HTTP protocol works, how APIs work, how forward and reverse proxies work, and how to use the Chrome Dev Tools. At the same time, over time ScrapeNinja has gained features that allow it to be used in no-code environments, for example the Extractor functionality allows you to extract pure JSON data from any HTML website using no-code tools like Make.com.
Useful Youtube videos related to web scraping:
Architecture
You can think of ScrapeNinja's rendering engines as of specially hardened Puppeteer (/scrape-js) and specially conditioned cURL (/scrape), which are designed to be interchangeable, so that Javascript extractor functions (which launch Cheerio on ScrapeNinja's servers) are designed to work identically on both engines.